
Punktskattningar av partiers röststöd i väljarbarometrar redovisas ofta med en decimals noggrannhet. Opinionsjournalister drar inte sällan stora växlar även på tiondelarna (inte minst om det handlar om partier som ligger nära riksdagsspärren!). Decimalerna ger en bedräglig bild av exakthet i skattningarna av partiernas röststöd. I de allra flesta situationer är tiondelsprecision inte motiverad eftersom konfidensintervall ofta kan vara två, tre, fyra ja ibland närmare sex procentenheter breda. (Inom opinions- och väljarforskningsbranschen skulle man få vara beredd att möta tuff kritik om man redovisade urvalsskattningar med onödigt hög precision; även i de största av våra undersökningar redovisar vi så gott som alltid procenttal avrundade till heltal.)
Exempel: Kring Miljöpartiets rekordnotering i Demoskop igår (10,6 procent) finns ett konfidensintervall på omkring +/- 1,9 procentenheter. Den statistiska inferensteorin har en tydlig definition av vad som avses med denna information: Vid upprepade urvalsförfaranden kommer konfidensintervallet kring urvalsskattningen att omsluta det sanna populationsvärdet i nittiofem fall av hundra (vid 95 procents säkerhetsnivå). Med sant värde menas i det här fallet andelen av samtliga röstberättigade svenskar som i en Demoskop-lik totalundersökning skulle svara ”Miljöpartiet” på frågan om hur de skulle rösta om det var riksdagsval idag (under perioden 24 februari-4 mars).
Det sanna populationsvärdet för Miljöpartiets röststöd känner förstås bara vår Herre till. Men tack vare inferensstatistikens sköna lagar kan vi faktiskt vara rätt säkra på att det sanna värdet för Miljöpartiets röststöd återfinns inom konfidensintervallet 8,7 och 12,5 procent. I nittiofem fall av hundra vill säga (vi har faktiskt ingen aning om huruvida en enskild mätning tillhör en av de nittiofem procenten lyckade fallen då konfidensintervallet träffar rätt eller ett av de fem procenten misslyckade). En absolut förutsättning för resonemanget är förstås att vi har med slumpmässiga urval att göra.
Konfidensintervallen krymper med urvalsstorlek. Ju större urval desto mindre intervall. För skattningar nära 50 procent är konfidensintervallen som störst. Skattningarna av de båda blockens storlek har följaktligen bredare konfidensintervall än små partier i närheten av fyra procent.
I tabellerna nedan har jag listat felmarginaler (gult) och konfidensintervall (blått) för partier med olika storlek (2, 4, 6, 8, 10, 20, 30, 40 och 50 procent) och undersökningar med olika stora urval (1000, 1500, 2700 och 6000 personer). För den som vill räknas till gruppen seriösa uttolkare av opinionsundersökningar är tabellen ett bra stöd. Skriv ut, plasta in och lägg i plånboken!
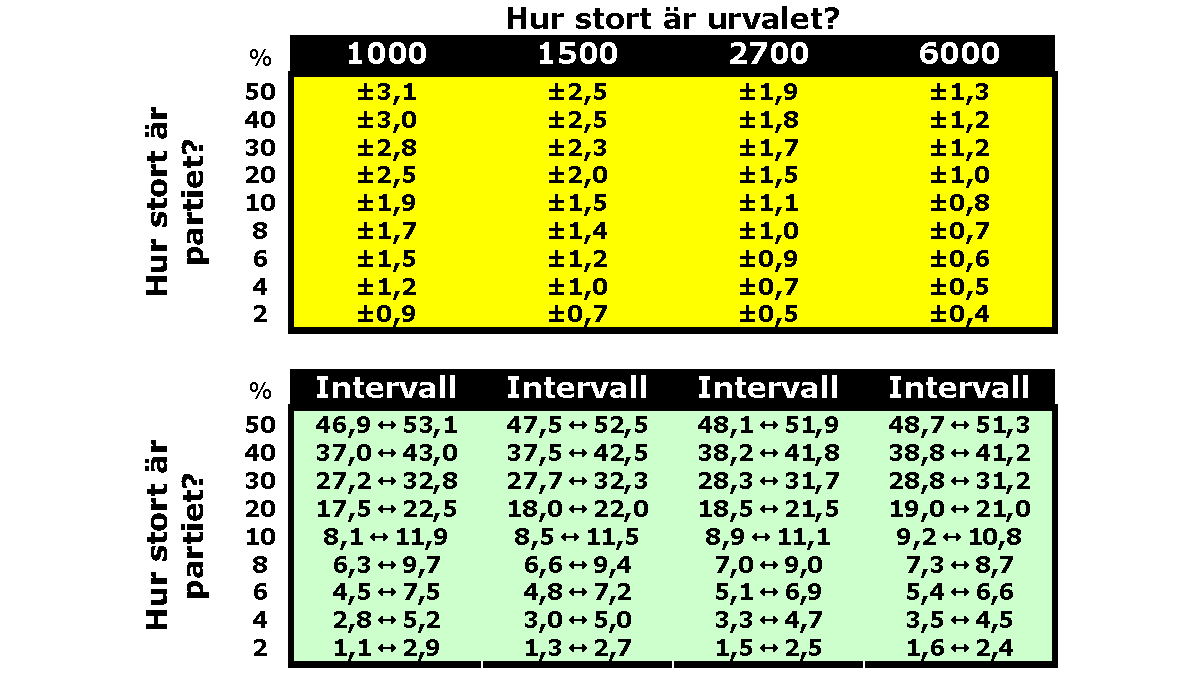
Här kan du själv få en känsla för hur stora konfidensintervallen är kring skattningar av partiers röststöd (proportioner).

Jag tycker att man endast borde redovisa heltal. Som du säger är decimalen bedräglig och många försöker \”förklara\” skillnader på säg 0,2 % med att det och det hänt den senaste månaden. Folk förstår inte att detta mer sannolikt beror på mätfel – och det är inte så konstigt heller, eftersom man förmedlar ett intryck av att man har bättre koll än man har genom att redovisa decimaler.I vissa andra länder verkar man oftast endast redovisa heltal (exvis Tyskland).
GillaGilla
I tidiga Sifo-mätningar avrundade man till hela eller halva procent, det var en bra modell tycker jag.Att var tjugonde konfidensintervall inte kommer att omsluta det sanna populationsvärdet är den risk vi ofta är beredda att ta. Det innebär samtidigt ytterligare ett skäl varför det är vettigt att slå samman resultat från många mätningar i en poll of polls.
GillaGilla
De som inte uppger parti eller inte påträffas är också en osäkerhet.Många av de som inte vill rösta på ett riksdagsparti kanske tilltalas av Piratpartiet, vad tror du om det?
GillaGilla
Som Bengt är inne på bör man kanske vara ännu mer försiktig när man tolkar enskilda mätningar, då en annan viktig felkälla är effekter av bortfall. Ovanstående \”säkerhetsnivåer\” förutsätter väl exempelvis obefintlig bias pga bortfall?En annan intressant fråga i sammanhanget är hur säker man kan vara på en opinionsförändring i en poll of polls?
GillaGilla
Svensk opinion har förstås rätt att inferensteorin förutsätter att eventuellt bortfall är slumpmässigt.Att använda poll of polls är ju egentligen ett slags källkritik: om flera oberoende mätningar bekräftar samma opinionsutveckling ökar förstås trovärdigheten. (Det förutsätter förstås att de mätningar man slår samman är tillräckligt jämförbara). Trenderna över tid känner jag mig säker på (bortfallet tenderar exempelvis att vara lika skevt ungefär hela tiden utom möjligen när några hundra tusen medelklass-svenskar samtidigt åker till Thailand på semester över jul och nyår) även om varsamhet påbjudes för nivåskattningar av partiers röststöd under sömniga mellanvalsperioder när det inte är skarpt läge (Långt ifrån alla väljare är heltaggade på politik jämt och ständigt).
GillaGilla
Piratpartiet överraskade vid EU-valet. De kan göra det i riksdagsvalet också.Tiderna och trenderna kan förändras. Jag tror att de har gjort det nu, med Internets hjälp
GillaGilla
När man snackar om opinionsmätningar, Om man tittar på Almegas uträkning om RUT avdraget så ser jag att de använt sig av en opinionsundersökning gjort på 1000 tillfrågade personer om deras attituder till RUT. De ställer följande fråga. Om skattereduktionen togs bort, dvs. du får betala hela kostnaden själv, hur skulle det påverka dittintresse för tjänsten?29 % av köparna säger att tjänsten blir ointressant. http://www.almega.se/MediaBinaryLoader.axd?MediaArchive_FileID=549f2d0d-cc4e-4735-999f-63aab01969f5&MediaArchive_ForceDownload=true(PDF fil sidan 7 )Den 29% siffran har väl då en felmarginal runt +/- 2,8 % i 95 fall av 100 ? Stämmer det eller är det något jag glömt ?
GillaGilla
Verkar stämma under förutsättning att 1 000 verkligen är procentbasen och att urvalet motsvarar ett obundet slumpmässigt urval (använder man andra slags sannolikhetsurval ser formlerna omedelbart annorlunda ut).
GillaGilla
Metodik som användes var något som heter CATI. Representativt urval av 1000 personer mellan 18 till 89 år. gjort 6-15 januari.
GillaGilla
Hej, du kanske skulle kunna lägga in felmarginalen i din poll of polls, antingen i form av errbars för varje enskild mätning eller kanske skuggade area för det viktade medelvärdet? Eller blir det för plottrigt?
GillaGilla
\”Skattningarna av de båda blockens storlek har följaktligen bredare konfidensintervall än små partier i närheten av fyra procent.\”Sperlar det någon roll för blockens konfidensinternvall om blockens procenttal är ihop-adderade av de mindre partierna, jag tänker att den additionen inte har inräknat intervallen för varje mindre parti?
GillaGilla
Staffan: Nej, det spelar ingen roll.
GillaGilla